The Data
As of November 2021, there are 23 million NUM data points available about 4.8 million UK companies, broken down as follows:
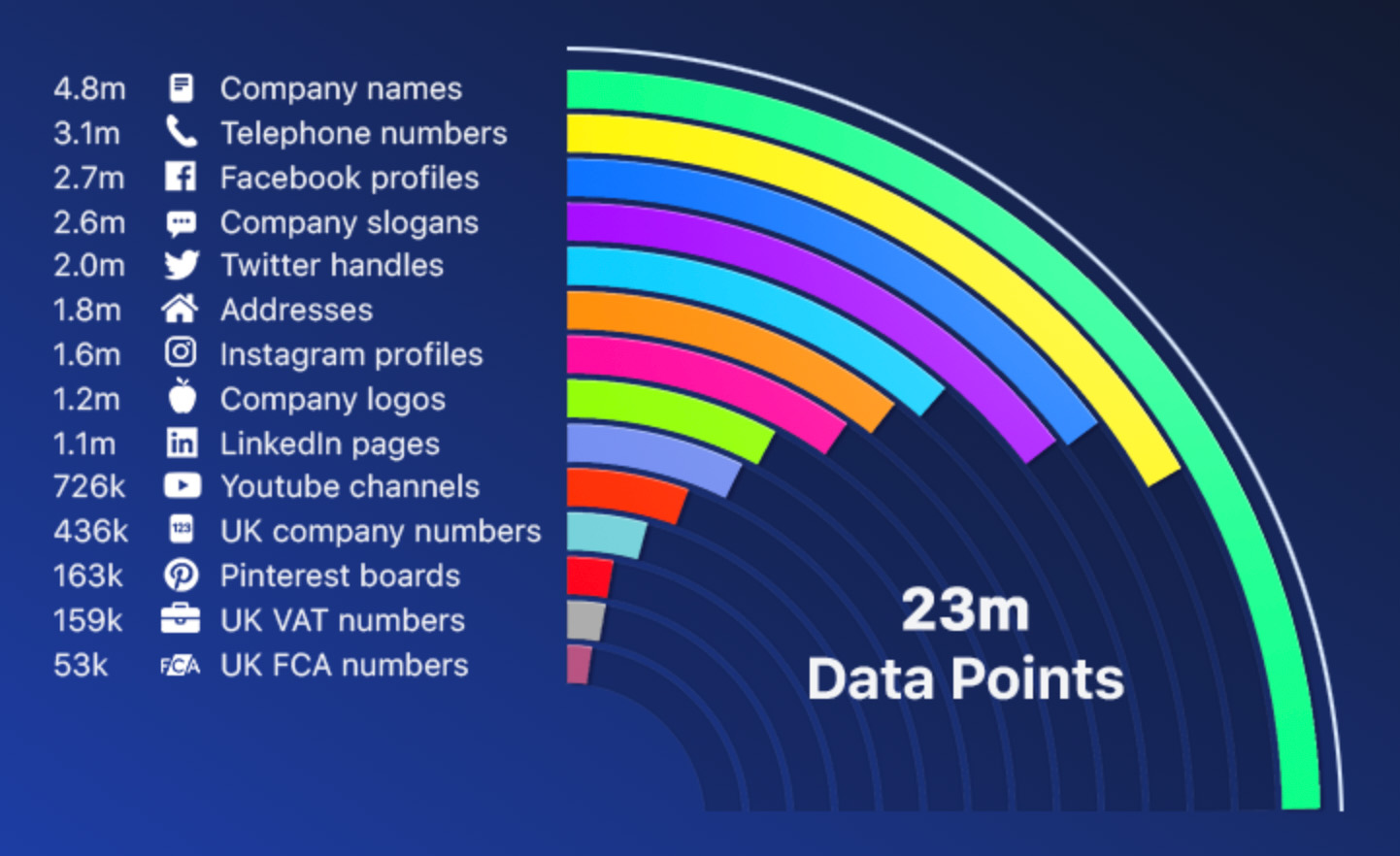
The Summary
We’re building a DNS-based alternative to the Semantic Web, providing the sort of data that's only previously been available through APIs offered by giants of the web. Unlike APIs, access to NUM data is available to developers free, unlimited and unrestricted. We’ve launched in the UK, pre-populating data for millions of domains and are rolling out internationally next year. Any domain owner can override their pre-populated data by adding NUM records to their own DNS or claim and update their pre-populated records using a simple user interface.
The Detail
The Semantic Web
The Semantic Web – the original "Web 3.0" proposed by Sir Tim Berners-Lee back in 1999 – was supposed to make information about organisations, people, places and things machine-readable. Sir Tim foresaw where we are today: we want to use an ever-increasing number of ways (apps, devices, assistants, services) to do an ever-increasing number of things, all requiring machines to understand online data.
1999: “The Semantic Web will enable machines to understand everything on the internet”
In the original vision, all of our devices would be able to understand an organisation and its offerings based solely on their website.
Let’s look at a few simple examples of what this would have enabled:
- Enter a URL into a vehicle to be navigated to the nearest store
- Dial a URL and select the most relevant phone number for an enquiry
- Accountancy software that can automatically fetch tax data for suppliers using their URL
Today the Semantic Web enables us to do none of these things.
2021: “The Semantic Web has enabled us to share fancy links on Facebook”
The majority of websites still don’t use the structured data formats that the Semantic Web relied upon (microdata, JSON-LD, RDFa). Of those that have adopted structured data formats, the overwhelming majority have only done so to the extent required so that users of Facebook, WhatsApp, Twitter, LinkedIn etc can share fancy links to webpages. Many of these don’t use real Semantic Web standards, opting instead for simpler, massively pared down standards created by Facebook (Open Graph), Twitter (card system) and others.
Complexity and chicken-and-egg
Outside of academia and research organisations, the general Semantic Web failed. One of the reasons it failed was because it was too complex for most businesses to adopt. Ultimately, not enough companies published machine-readable data to make it generally and reliably useful so that apps, devices, assistants and services could be built on top of it. In other words, it failed because of the chicken-and-egg problem.
Gatekeepers of the web
Our ever-increasing need for machine-readable data combined with the failure of the Semantic Web has resulted in the rise of centralised APIs offered by the giants of the web. Companies like Alphabet have built an empire by crawling the web, indexing its content and storing it in their Knowledge Graph. They’ve built devices, apps, services, operating systems and entire ecosystems on top of this data.
Developers looking to build apps that use machine-readable data about organisations are faced with two options:
- Crawl the web as Alphabet have done, store that data and try to keep it up to date
- Use a paid, restricted, rate limited API
Option 1 is outside the realms of possibility for most developers and would only serve to fragment internet data further. Option 2 comes with rate limits and use restrictions that are designed to limit competition. The result is stifled creativity of millions of developers and users left with little choice but to use privacy-compromising apps offered by the giants of the web.
In the same way that organisations can independently deliver human-readable websites direct to customers using the web’s open standards; organisations need to be able to provide machine-readable data direct to devices, apps and services used by their customers. This is the challenge the Semantic Web failed to meet and as a result, the giants of the web became the gatekeepers of the web.
The way the web's gatekeepers make data available to developers through APIs only further entrenches their position. This has to change.
An alternative to the Semantic Web
At NUM, we’re building an alternative to the Semantic Web - an open standard to publish machine-readable data associated with domain names.
Almost all online organisations have a domain name - it’s their unique identifier and little piece of the internet. The World Wide Web and email are two of the most successful standards ever created and both are built on top of the Domain Name System (DNS).
NUM is built on top of the DNS too, but crucially doesn’t suffer from the same chicken-and-egg problem that killed the Semantic Web because we’ve pre-populated the DNS with useful data.
An open standard that works from day one
Any domain name owner can adopt NUM by publishing NUM Records (specially formatted DNS TXT records) to their own DNS. We provide a simple tool to build records, these records can then be copied and pasted into tools offered by DNS providers.
Of course, this method of adoption alone would condemn NUM to the same fate as the Semantic Web. So there's another way to adopt NUM, through a huge DNS data store called the NUM Server and we've pre-populated it with millions of NUM Records.
Any organisation can update the data stored in the NUM Server by claiming their domain name using a simple user-friendly interface.
Public data served out of public DNS
To start with, we’ve published all the useful, open, public data we can find about UK companies to the NUM Server. This data is published within the DNS of the domain name NUM.NET, which the NUM protocol uses as a secondary, fail over query location if NUM hasn’t been adopted in the authoritative DNS of a domain. If you're interested you can dig into how it all works here.
To find this data we crawled 18 million domains for UK companies and found around five million active company websites with useful public data. From these we extracted contact data, logos, company numbers, VAT numbers and more. We matched and mashed this data up with other open, public data sources like Companies House and published all this data to DNS in the form of NUM records - almost 10 million of them.
Free, unlimited, unrestricted access for everyone forever
We make all this data available in DNS because it’s one of the most efficient ways to store and serve small packets of data, partly due to the cached and distributed nature of DNS. By storing and serving data using DNS we can’t track, limit or restrict use even if we wanted to - which we absolutely don’t.
Our goal is for NUM to be a utility, just like DNS. Something everyday internet users use all the time without realising. Developers can use it today and build apps with our open source libraries.
In the UK right now, NUM can fulfil some of the promises of the Semantic Web:
- Enter a URL into a vehicle to be navigated to the nearest store
- Dial a URL and select the most relevant phone number for an enquiry
- Accountancy software that can automatically fetch tax data for suppliers using their URL
More broadly, NUM is a way to create and adopt standards, we call these modules and over time we hope NUM will be used to fulfil the potential of the machine-readable web.
Example apps
To take a look at how NUM can be used to solve real problems for real users, check out CompanyDirectory.UK – a directory of some of the UK's largest companies, with all of their contact information provided in a simple, searchable list. All powered by NUM.
First the UK, next the World
There's more work to do but we've proven NUM can be used to provide useful machine-readable data about UK companies. Next, we’ll roll out internationally, starting with the US.
Feedback very welcome
We’d love to hear your feedback and invite you to get in touch.